구조적 데이터 표시와 처리에 강한 pandas
Series를 활용한 데이터 생성
import pandas as pd
s1 = pd.Series([10, 20, 30, 40, 50])0 10
1 20
2 30
3 40
4 50
dtype: int64
데이터가 없을 경우 Numpy를 import 하여 데이터 없음 표기 가능
import numpy as np
s3 = pd.Series([np.nan,10,30])
s3
0 NaN
1 10.0
2 30.0
dtype: float64인자로 index 추가
index_date = ['2018-10-07','2018-10-08','2018-10-09','2018-10-10']
s4 = pd.Series([200, 195, np.nan, 205], index = index_date)
s4
2018-10-07 200.0
2018-10-08 195.0
2018-10-09 NaN
2018-10-10 205.0
dtype: float64날짜 자동 생성
pd.data_range(start = None, end = None, periods = None, freq='D')
import pandas as pd
pd.date_range(start='2019-01-01',end='2019-01-07')
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07'],
dtype='datetime64[ns]', freq='D')periods 사용하기 - 개수 지정
pd.date_range(start='2019-01-01', periods = 7)
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07'],
dtype='datetime64[ns]', freq='D')freq 사용하기 - 단계 설정
pd.date_range(start='2019-01-01', periods = 4, freq = '2D')
DatetimeIndex(['2019-01-01', '2019-01-03', '2019-01-05', '2019-01-07'], dtype='datetime64[ns]', freq='2D')요일 시작 기준 일주일 주기 freq = 'W', freq = 'W-MON'
pd.date_range(start='2023-01-01', periods = 5, freq = 'W-mon')
DatetimeIndex(['2023-01-02', '2023-01-09', '2023-01-16', '2023-01-23',
'2023-01-30'],
dtype='datetime64[ns]', freq='W-MON')업무 월말 날짜 기준 주기 freq = 'BM', freq = '2BM'
pd.date_range(start='2023-01-01', periods = 12, freq = '2BM')
DatetimeIndex(['2023-01-31', '2023-03-31', '2023-05-31', '2023-07-31',
'2023-09-29', '2023-11-30', '2024-01-31', '2024-03-29',
'2024-05-31', '2024-07-31', '2024-09-30', '2024-11-29'],
dtype='datetime64[ns]', freq='2BM')분기 시작 기준 날짜 주기
freq = 'QS' , freq = '2QS'
연도 기준 날짜 주기
freq = 'AS' , freq = '2AS'
시간 기준 주기 등등
freq = 'H'
DataFrame을 활용한 데이터 생성
2차원 데이터를 위해서 DataFrame를 사용
import pandas as pd
pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
Numpy의 배열 데이터를 활용한 DataFrame 생성
import numpy as np
import pandas as pd
data_list = np.array([[10, 20, 30], [40, 50, 60], [70, 80, 90]])
pd.DataFrame(data_list)
index와 colums 지정
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8 ,9], [10, 11, 12]])
index_date = pd.date_range('2019-09-01', periods=4)
columns_list = ['A', 'B', 'C']
pd.DataFrame(data, index=index_date, columns=columns_list)
딕셔너리 타입으로 2차원 데이터를 입력했을 경우
table_data = {'연도': [2015, 2016, 2016, 2017, 2017],
'지사': ['한국', '한국', '미국', '한국','미국'],
'고객 수': [200, 250, 450, 300, 500]}
pd.DataFrame(table_data)
지정한 순서대로 출력하기
pd.DataFrame(table_data, columns=['연도', '고객 수', '지사'])
데이터를 원하는 대로 선택하기
KTX_data = {'경부선 KTX': [39060, 39896, 42005, 43621, 41702, 41266, 32427],
'호남선 KTX': [7313, 6967, 6873, 6626, 8675, 10622, 9228],
'경전선 KTX': [3627, 4168, 4088, 4424, 4606, 4984, 5570],
'전라선 KTX': [309, 1771, 1954, 2244, 3146, 3945, 5766],
'동해선 KTX': [np.nan,np.nan, np.nan, np.nan, 2395, 3786, 6667]}
col_list = ['경부선 KTX','호남선 KTX','경전선 KTX','전라선 KTX','동해선 KTX']
index_list = ['2011', '2012', '2013', '2014', '2015', '2016', '2017']
df_KTX = pd.DataFrame(KTX_data, columns = col_list, index = index_list)
df_KTX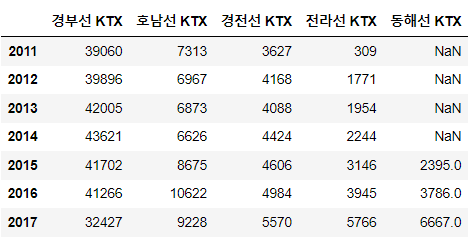
df_KTX.index
Index(['2011', '2012', '2013', '2014', '2015', '2016', '2017'], dtype='object')df_KTX.columns
Index(['경부선 KTX', '호남선 KTX', '경전선 KTX', '전라선 KTX', '동해선 KTX'], dtype='object')df_KTX.values
array([[39060., 7313., 3627., 309., nan],
[39896., 6967., 4168., 1771., nan],
[42005., 6873., 4088., 1954., nan],
[43621., 6626., 4424., 2244., nan],
[41702., 8675., 4606., 3146., 2395.],
[41266., 10622., 4984., 3945., 3786.],
[32427., 9228., 5570., 5766., 6667.]])앞뒤 일부만 출력하기
df_KTX.head(), df_KTX.tail()
지정한 수 만큼 출력하기
df_KTX.head(3), df_KTX.tail(2)
DataFrame에서 연속된 구간의 행 데이터를 선택하기
DataFrame_data[행_시작 : 행_끝]
index를 지정하기
DataFrame_data.loc[index_name]
구간을 지정해서 출력하기
df_KTX.loc['2013':'2016']
하나의 열 데이터를 출력하기
df_KTX['경부선 KTX']
하나의 열 데이터에서 index 범위 지정하기
DataFrame_data [column_name] [start_index_name : end_index_name]
DataFrame_data [column_name] [start_index_pos : end_index_pos]
DataFrame 중 하나의 원소만 선택하기
DataFrame_data.loc [index_name] [column_name]
DataFrame_data.loc [index_name, column_name]
DataFrame_data.loc [column_name] [index_name]
DataFrame_data.loc [column_name] [index_pos]
DataFrame_data.loc [column_name].loc [index_name]
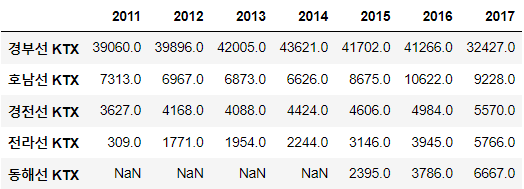
행과 열을 바꾸기
df_KTX.T
데이터 통합하기
인덱스 순차적으로 연결시키기
ignore_index=True
index의 라벨을 지정한 경우에도 index가 맞다면 join이 가능
index_label = ['a','b','c','d']
df1a = pd.DataFrame({'Class1': [95, 92, 98, 100],
'Class2': [91, 93, 97, 99]}, index = index_label)
df4a = pd.DataFrame({'Class3': [93, 91, 95, 98]}, index =index_label)
df1a.join(df4a)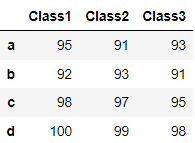
크기가 다른경우 - NaN값으로 표시
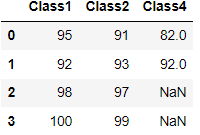
두 개의 데이터에 공통된 열(key)이 있다면 이 열의 기준으로 통합가능
df_A_B = pd.DataFrame({'판매월': ['1월', '2월', '3월', '4월'],
'제품A': [100, 150, 200, 130],
'제품B': [90, 110, 140, 170]})
df_C_D = pd.DataFrame({'판매월': ['1월', '2월', '3월', '4월'],
'제품C': [112, 141, 203, 134],
'제품D': [90, 110, 140, 170]})
df_A_B.merge(df_C_D)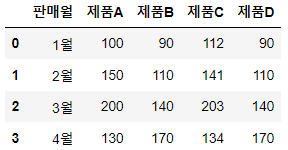
일부만 공통 된 값을 갖는 경우
DataFrame_left_data.merge(DataFrame_right_data , how = merge_method, on = key_label)
on = 통합할 인자 입력 ( 입력하지 않으면 공통 된 열 자동설정)
how = 지정 된 열(key)을 기준으로 통합 방법(merge_method) 지정

데이터 파일을 읽고 쓰기
표 형식의 데이터 파일을 읽기
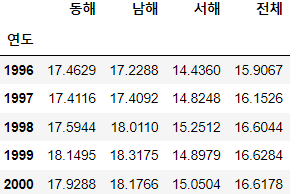
%%writefile C:\code\myPyCode\data\sea_rain1.csv
연도,동해,남해,서해,전체
1996,17.4629,17.2288,14.436,15.9067
1997,17.4116,17.4092,14.8248,16.1526
1998,17.5944,18.011,15.2512,16.6044
1999,18.1495,18.3175,14.8979,16.6284
2000,17.9288,18.1766,15.0504,16.6178
pd.read_csv('C:/code/myPyCode/data/sea_rain1_from_notepad.csv', encoding = "cp949"자동으로 설정 된 index가 아닌 특정 열을 지정하고 싶을 때
index_col = '연도'
'[Python]' 카테고리의 다른 글
| [Python] 빅데이터분석기사 기초 통계 (1) | 2023.10.26 |
|---|---|
| [Python] 빅데이터분석기사 실기 연습(작업형2) (0) | 2023.10.18 |
| [Python] 빅데이터분석기사 실기 연습(작업형1) (0) | 2023.10.18 |
| [Python] 통계 기본 정리 (0) | 2023.04.03 |
| [Python] Numpy 기본 (0) | 2023.03.06 |